
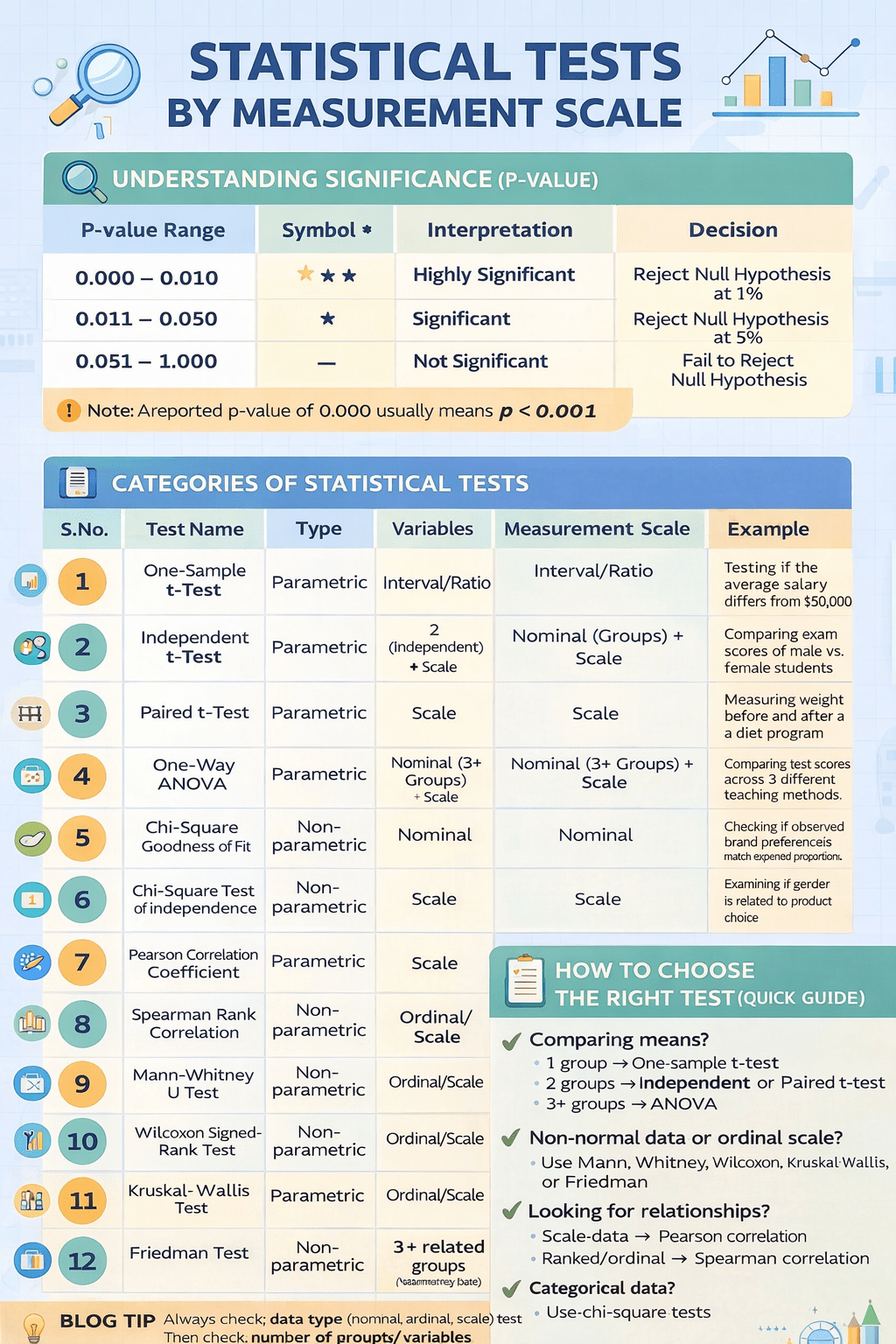
🌟 Introduction
Classification problems are everywhere:
- Will a customer churn or stay?
- Is a transaction fraudulent or genuine?
- Does a patient have a disease or not?
Two of the most important and widely used algorithms for such tasks are:
- Logistic Regression – simple, interpretable, probabilistic
- Support Vector Machine (SVM) – powerful, margin-based, geometric
Though very different in philosophy, both are core supervised learning models and often serve as baseline and benchmark models in real projects.
🔵 Logistic Regression
📌 What is Logistic Regression?
Logistic Regression is a classification algorithm that models the probability of an event occurring.
Despite the name, it is not a regression model for continuous outputs.
It predicts class probabilities, typically for binary classification.
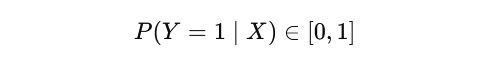
🧩 Logistic Regression – Conceptual View
Key ideas:
- Linear combination of features
- Passed through a sigmoid (logistic) function
- Output interpreted as probability
🧮 Mathematical Formulation

📊 Example: Customer Churn Prediction
Problem:
Predict whether a customer will churn (Yes/No).
Features:
- Monthly charges
- Tenure
- Number of complaints
Suppose the fitted model is:
z = −3 + 0.02 (Monthly Charges) − 0.05 (Tenure)
For a customer with:
- Monthly charges = 2000
- Tenure = 12

📌 Since probability > 0.5 → Customer predicted to churn
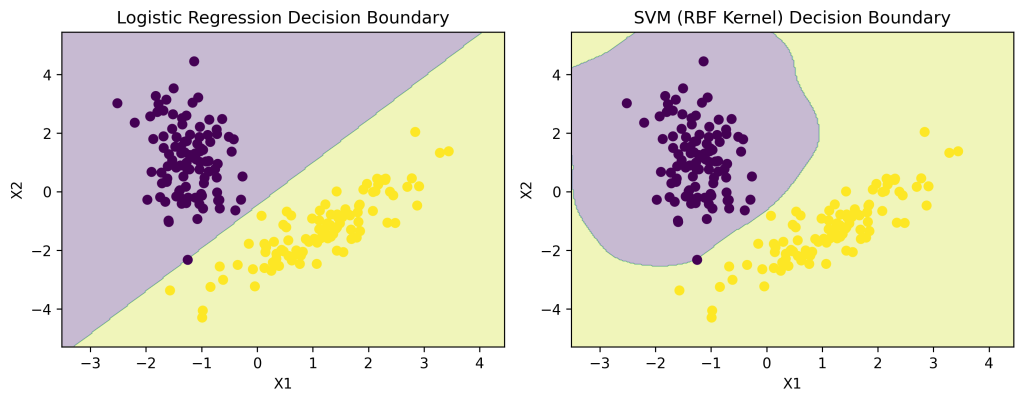
📈 Logistic Regression Decision Boundary
- Linear boundary in feature space
- Can be extended to non-linear boundaries using feature engineering
✅ Advantages of Logistic Regression
✔ Simple and fast
✔ Highly interpretable coefficients
✔ Probabilistic output
✔ Works well with small datasets
❌ Limitations
✘ Assumes linear decision boundary
✘ Struggles with complex non-linear data
✘ Sensitive to outliers
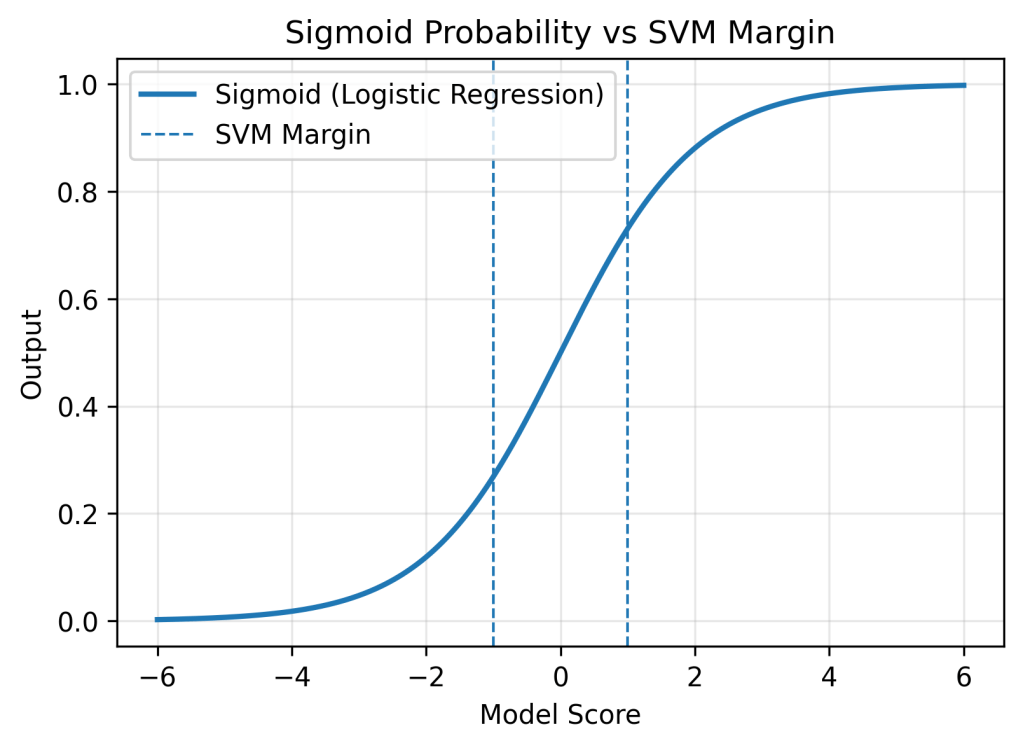
🔴 Support Vector Machine (SVM)
📌 What is SVM?
Support Vector Machine (SVM) is a margin-based classifier that finds the optimal separating boundary between classes.
Instead of modeling probability, SVM focuses on geometry.
“Find the line (or plane) that separates classes with the maximum margin.”
🧩 SVM – Conceptual View
Key ideas:
- Decision boundary (hyperplane)
- Margin – distance between boundary and nearest points
- Support vectors – critical boundary points
🧮 Mathematical Intuition (Simplified)

📊 Example: Email Spam Classification
Features:
- Frequency of suspicious words
- Email length
- Number of links
SVM:
- Identifies emails closest to boundary (support vectors)
- Draws a hyperplane maximizing separation
📌 Very effective when classes overlap slightly.
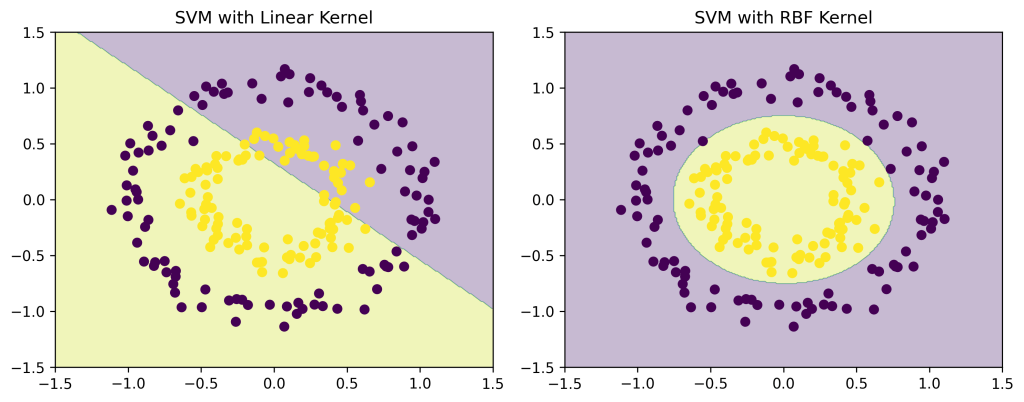
🌀 Kernel Trick: Handling Non-Linearity
SVM can handle non-linear boundaries using kernels.
Common kernels:
| Kernel | Use |
|---|---|
| Linear | Large, linearly separable data |
| Polynomial | Curved boundaries |
| RBF (Gaussian) | Complex non-linear patterns |
| Sigmoid | Neural-network-like |
⚙️ Key Hyperparameters in SVM
- C (Regularization)
- High C → less misclassification, smaller margin
- Low C → wider margin, more tolerance
- Kernel parameters (γ, degree)
Control shape of boundary
✅ Advantages of SVM
✔ Powerful for high-dimensional data
✔ Effective with small datasets
✔ Robust to overfitting (with tuning)
❌ Limitations
✘ Computationally expensive for large datasets
✘ Harder to interpret
✘ Sensitive to kernel choice
🔁 Logistic Regression vs SVM
| Aspect | Logistic Regression | SVM |
|---|---|---|
| Approach | Probabilistic | Geometric |
| Output | Probability | Class label |
| Boundary | Linear | Linear / Non-linear |
| Interpretability | High | Low |
| Performance | Moderate | High |
| Scalability | Very good | Slower |
🧪 Python Example
from sklearn.linear_model import LogisticRegression
from sklearn.svm import SVC
# Logistic Regression
log_reg = LogisticRegression()
log_reg.fit(X_train, y_train)
# SVM
svm = SVC(kernel='rbf', probability=True)
svm.fit(X_train, y_train)
🌍 Real-World Applications
| Industry | Logistic Regression | SVM |
|---|---|---|
| Finance | Credit risk | Fraud detection |
| Healthcare | Disease risk | Medical image classification |
| Marketing | Churn prediction | Customer segmentation |
| Text Analytics | Sentiment classification | Spam detection |
| Manufacturing | Failure probability | Defect detection |
⚠️ Common Pitfalls
- Interpreting SVM outputs as probabilities (without calibration)
- Using Logistic Regression on highly non-linear data
- Poor kernel and hyperparameter tuning in SVM
- Ignoring class imbalance
🧾 Key Takeaways
✔ Logistic Regression is simple, interpretable, and probabilistic
✔ SVM is powerful, margin-based, and flexible
✔ Logistic Regression explains, SVM separates
✔ Model choice depends on data size, complexity, and explainability needs
📚 References & Further Reading
- Hastie, T., Tibshirani, R., & Friedman, J. (2017). The Elements of Statistical Learning. Springer.
- James, G., et al. (2021). An Introduction to Statistical Learning. Springer.
- Cortes, C., & Vapnik, V. (1995). Support-Vector Networks. Machine Learning.
- Géron, A. (2022). Hands-On Machine Learning. O’Reilly.
- scikit-learn Documentation
- Logistic Regression
- Support Vector Machines





Leave a comment